Introduction
These datasets are collected by Atheros CSI Tool and used in our teams's publications.
There are 3 datasets in total.
Dataset1 is for paper “Domain-Agnostic Sample-Effcient Wireless Indoor Crowd Counting via Few-shot Learning”.
Dataset2 is for paper “ResMon: Domain-adaptive Wireless Respiration State Monitoring via Few-shot Bayesian Deep Learning”.
Dataset3 is for paper “Few-shot learning based robust cross-scenario fatigue detection system”.
Dataset1: DASECount
Formats
This dataset is for paper “Domain-Agnostic Sample-Effcient Wireless Indoor Crowd Counting via Few-shot Learning”, which has been submitted for potential journal publication. The conference version is available in IEEE WOCC 2022 . The dataset contains 9 “pickle” file in total. Each file contains split CSI amplitude data, phase difference data and labels. Data collection scenarios are shown as follows:
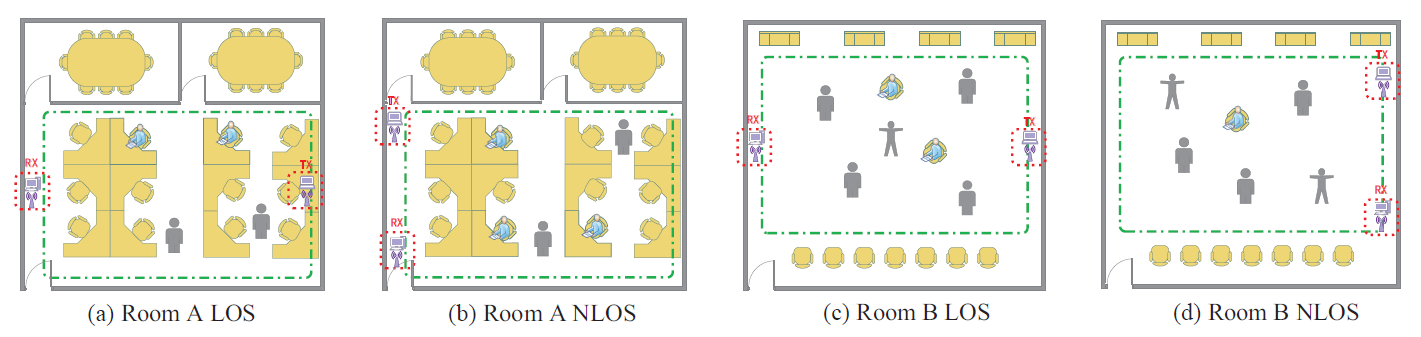 |
Each scenario contains three crowd motion types data: Static, Dynamic and Mixed.
Static: volunteers are required to remain seated but can act freely, such as eating, typing, or sleeping;
Dynamic: volunteers walk randomly walk around the venue;
Mixed: there is no restriction to the volunteers’ activities, and they can move freely in the venue including but not limited to walking, sitting, eating, and sleeping.
Each type data contains a crowd range of 0-8 people. And each class contains 600 samples.
Download Links
Usage in Python
import pickle
import numpy
with open(“office_los_static.pickle”, “rb”) as file:
dataset = pickle.load(file)
csi_amp = dataset[“abs”]
csi_pha = dataset[“phase_df”]
csi_label = dataset[“labels”]
“abs”: original amplitude data from split CSI stream.
“phase_df”: phase difference data, by computing difference between two adjacent receiving antennas.
“labels”: label of data, is the same as the number of people in the scene.
Dataset2: ResMon
Formats
This dataset is for paper “ResMon: Domain-adaptive Wireless Respiration State Monitoring via Few-shot Bayesian Deep Learning”, which has been submitted for potential journal publication. The dataset contains 6 “zip” files in total. Each file contains 4 respiration state classes (i.e. stable breath, cough, sneeze, and yawn) of CSI sample files. These sample are collected in two indoor environments, i.e., a lab and a meeting room, containing one source domain area and two target domain areas, as shown in the follows:
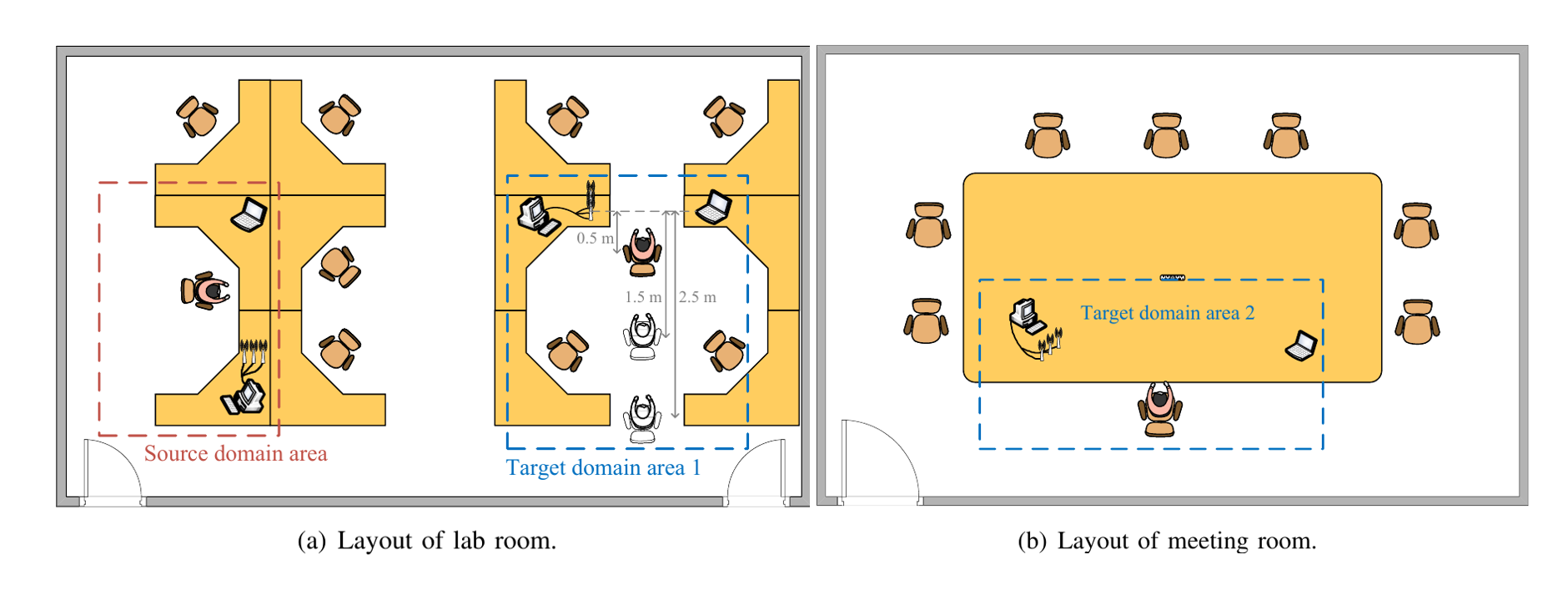 |
The source domain dataset totally consists of 720 samples for volunteer A, B and C. The target domain dataset 1 and 2 respectively consists of 200 samples for volunteer A to F. In additions, 5 time serial samples and the subdatasets collected under different distances, operating frequency band are also included in target domain 1.
Download Links
Usage in Python
import numpy as np
data=np.load(’S_COUGH.npy’)
A subdataset under “cough” label in source domain
Dataset3: Fatigue detection
Formats
This dataset is for paper “Few-shot learning based robust cross-scenario fatigue detection system”, which has been submitted for potential journal publication. The dataset contains 24 “mat” files in total. The dataset are CSI amplitude and phase difference files on 6 volunteers. Each file has a certain number of four types of fatigue actions (i.e., yawn-1, rubbing eyes-2, nod-3, and stillness-4). These samples are collected in two indoor environments which are defined as source domain (meeting room) and target domain (office room), as shown in the follows:
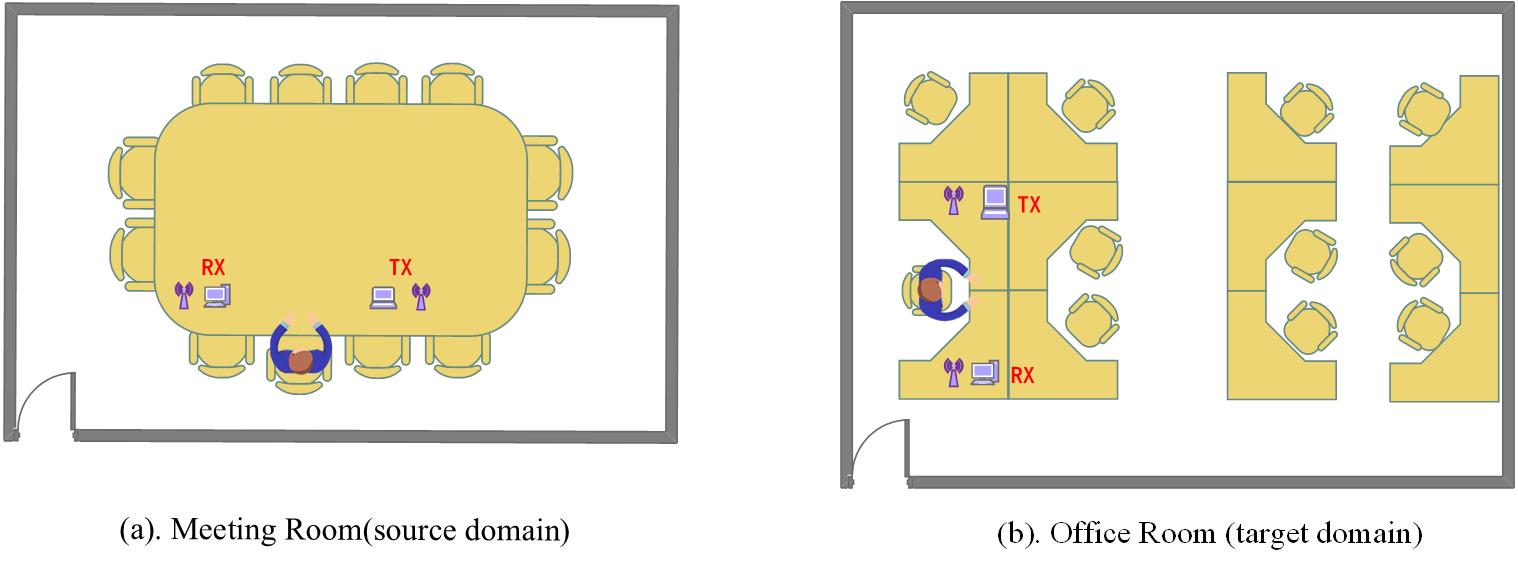 |
We ask each volunteer to take 50 times in source domain and 40 times in target domain for each class of fatigue actions. The source domain dataset totally consists of 1200 (50×4×6) samples on six volunteers. The target domain dataset consists of 960 (40×4×6) samples on six volunteers.
Download Links
Usage in Python
import scipy.io as scio
import xlrd
data = scio.loadmat(matfile_path)
label=xlrd.open_workbook(“label_path”).sheet_by_name('Sheet1’).col_values(0)